光学字符识别(选做)
概要
经过本次课程实验, 你将能利用所学的图像处理知识, 结合matlab实现一个完整的光学字符识别系统(OCR).
整个课程的全部代码点此下载, 点开OCR.m文件并运行即可.
在上方的matlab学习资料可以找到matlab相关教程.
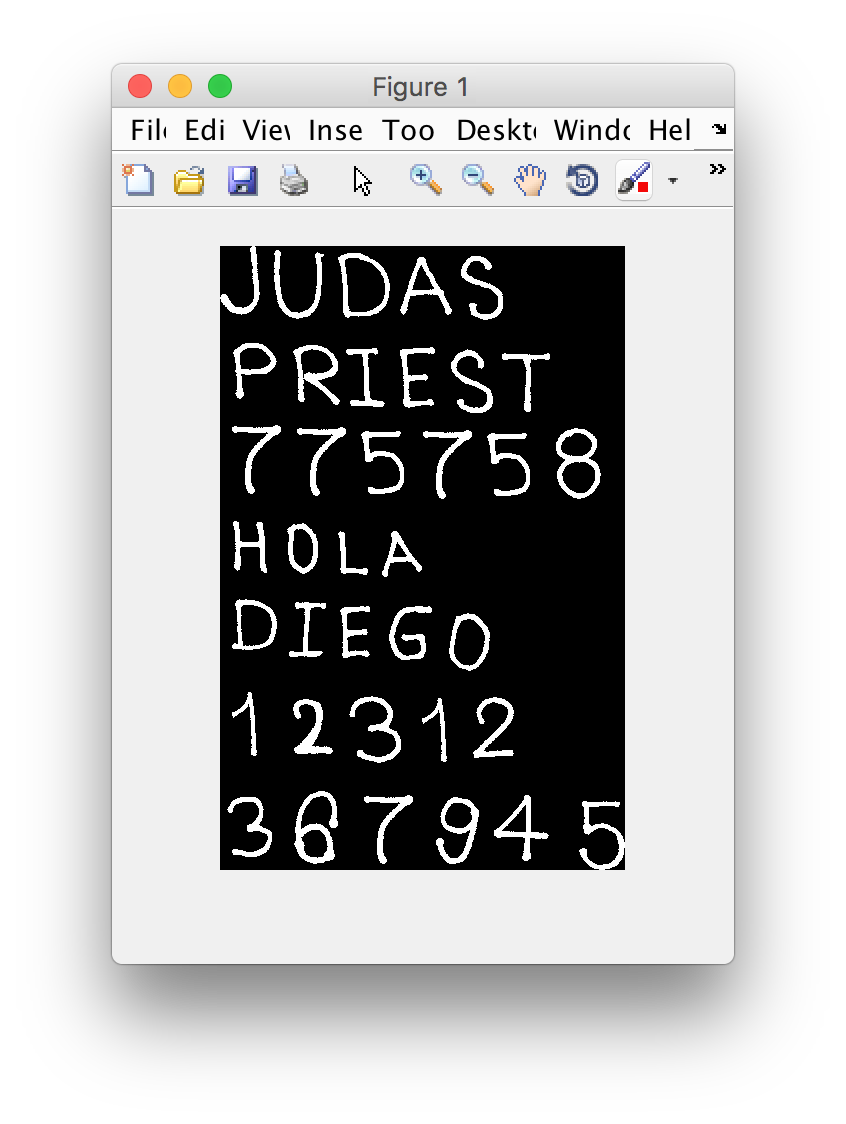
结果演示
OCR系统教程
1. 初始化
首先, 我们需要清空系统存储的变量及将想要进行字符识别图像的图片文件名字保存在matlab上, 此处input命令相当于c语言的scanf, 等待外部输入并将值传递给str_.
%% ==================== 第一部分: 初始化 ====================
warning off %#ok<WNOFF>
%清空环境变量
clc, close all, clear all
%再此输入要识别的图片名字
str_ = input('请输入想要进行测试的图片编号 比如: 1 :>> ','s');
%如果需要用自己的图片, 图片命名规范为: TEST_2.JPG , 其中2可以为其他的编号
img = sprintf('TEST_%s.jpg',str_);
2. 显示图片
为了在Matlab中读取图片, 使用imread命令读取即可获取图像的像素矩阵, 对于彩色的图片Matlab会将其转换为XY3的矩阵, 其中每一个像素点都是有三个值(R,G,B), 分别代表红, 绿, 蓝三种颜色的分量.
%% ==================== 第二部分: 显示图片 ====================
%读取要识别的图像
imagen=imread(img);
在Matlab中显示图片只需要使用imshow命令, 后面接title可以为显示的图像增加标题.
%显示图像
imshow(imagen);
title('带噪声的输入图像')
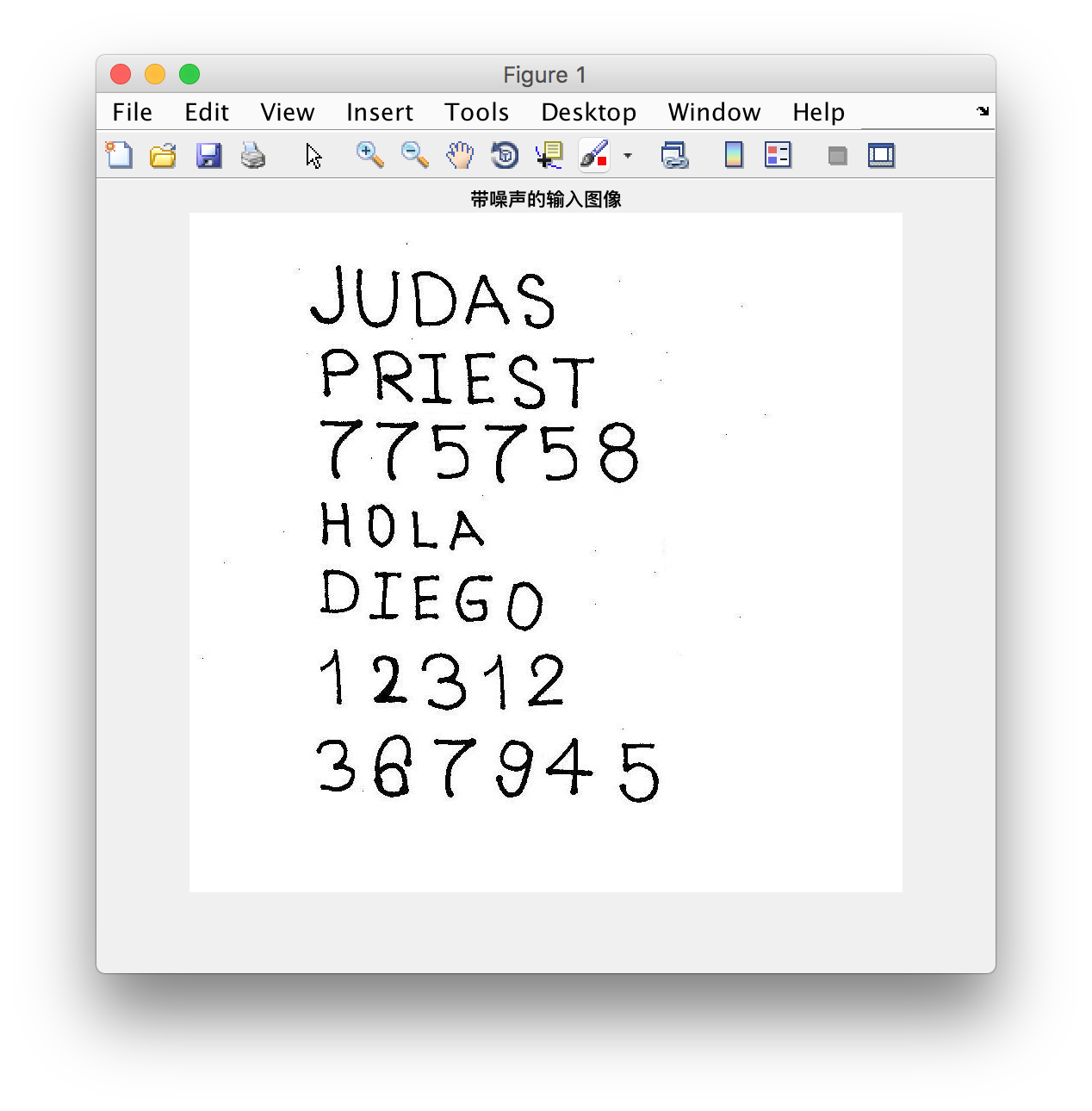
3. 二值化
由于我们进行字符识别的时候并不关心字符本身的颜色, 而是字符的形状, 并利用其形状对其代表的符号进行识别, 所以我们需要将原来的RGB颜色矩阵转换成01矩阵, 以此得到最有用的信息, 消去不必要的信息.
为了进行二值化, 我们首先要得到一个灰度矩阵(二维矩阵)而非RGB这样一个三维矩阵. 对于彩色图片, 我们首先需要进行灰度变换将原来的三维矩阵转换成二维矩阵以进一步二值化, 在matlab中我们可以直接调用rgb2gray函数进行灰度化.
%% ==================== 第三部分: 二值化 ====================
%如果是RGB图像, 转换成灰度图像
if size(imagen,3)==3 %RGB image
imagen=rgb2gray(imagen);
end
得到二维的灰度矩阵后, 我们需要找到一个二值化的阈值以对灰度图像矩阵进行0,1变换, 在Matlab中, 我们可以调用graythresh得到一个灰度图像比较合适的二值化阈值, 之后就可以利用该阈值对图像进行二值化.
%计算二值化阈值
threshold = graythresh(imagen);
%二值化
imagen =~im2bw(imagen,threshold);
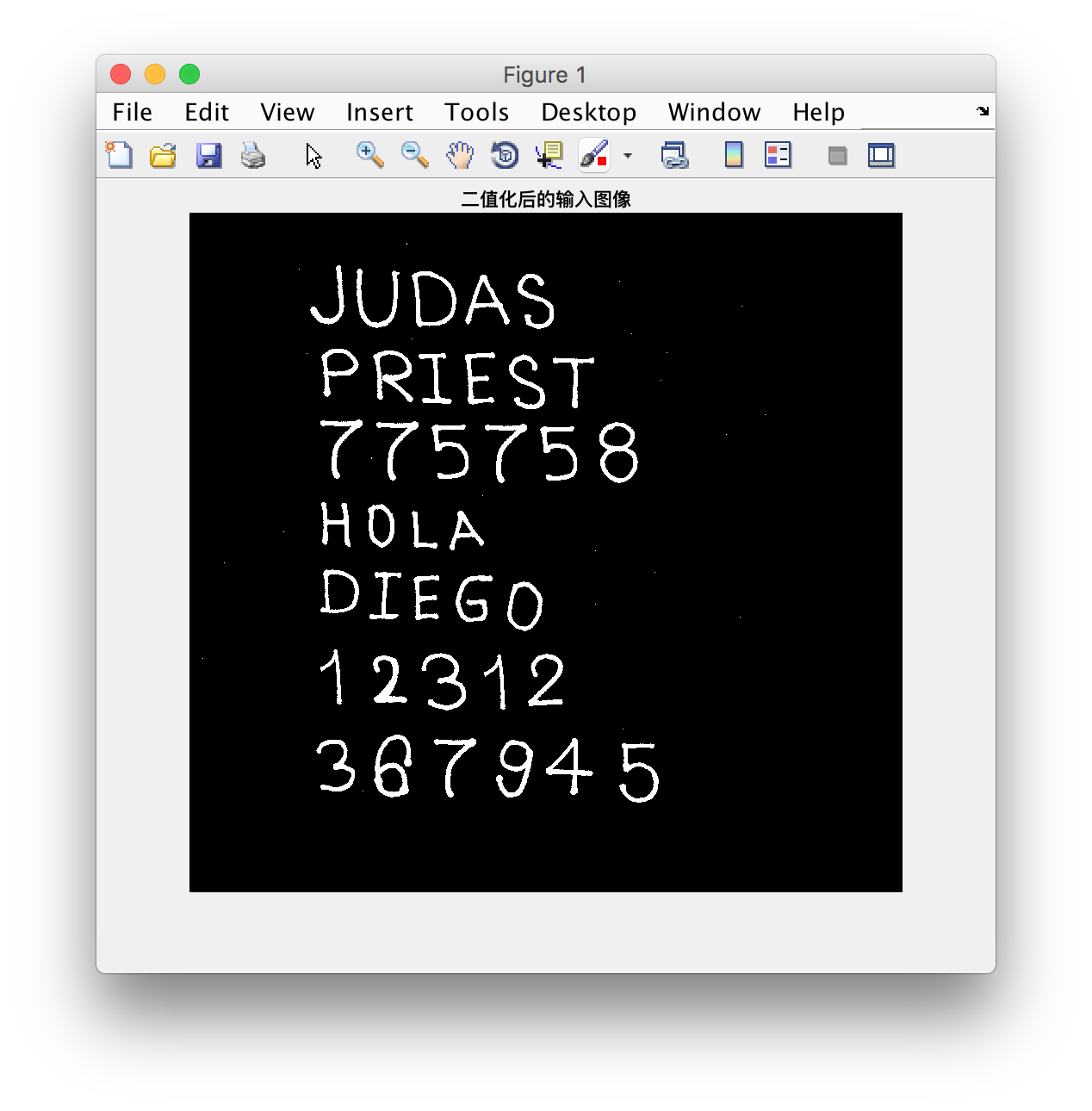
其中im2bw命令接受一个灰度图像及一个二值化阈值对图像进行分割, 返回分割后的二值化矩阵, 此处用~进行取反是为了将字符上的像素值转换为1而非0, 可以看到存在少量的白色小噪声, 这会影响识别的结果, 我们需要提前进行处理.
4. 去除噪声
二值化后的图像会存在很多细小的白色噪声, 影响字符的识别效果. 一个简单的去除细小噪声的方法就是消除连通量小于一定值的白色连通块.
% 移除像素个数少于30的连通量
imagen = bwareaopen(imagen,30);
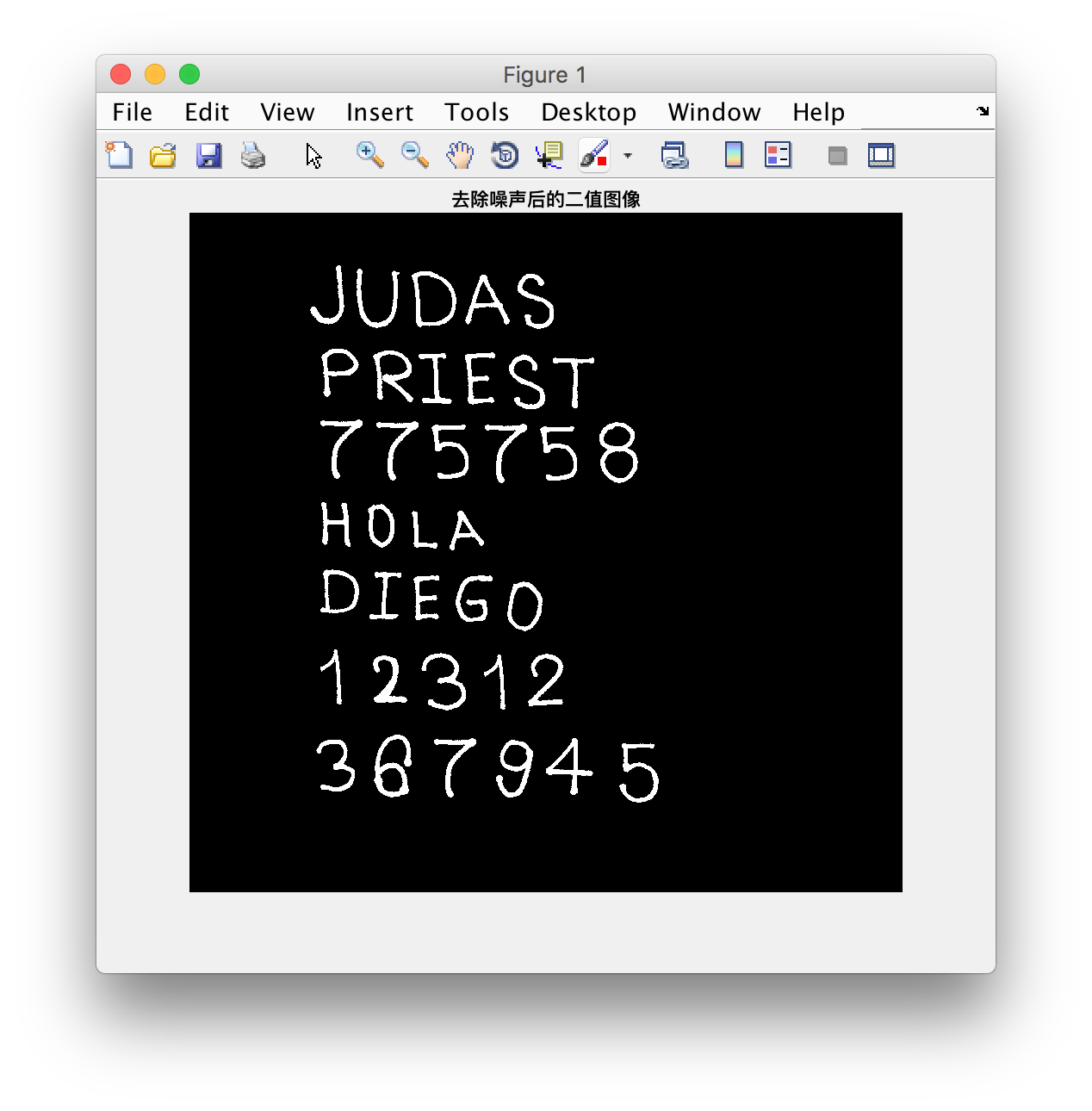
bwareaopen命令接受一个二值化矩阵及最小连通量阈值, 其会将连通量小于该阈值的连通块直接消去, 得到的效果就是细小的白色噪声被消去.
5. 加载模板
为了对处理后的图片进行识别, 我们将采用最简单的矩阵相似度来进行匹配识别. 我们提供了字符模板作为比较匹配, 当找到与待识别图像矩阵最相似的已识别图像矩阵, 就将其字符标记作为我们待识别图像矩阵的标记返回.
这里我们提供了从数字0-9, 字母A-Z一共36种最常见字符的模板, 如下图所示, 这些模板都是有字符标记的图像. 我们现在要做的是对一个新的未知图像去识别其对应的字符标记.
提供的模板图像如下
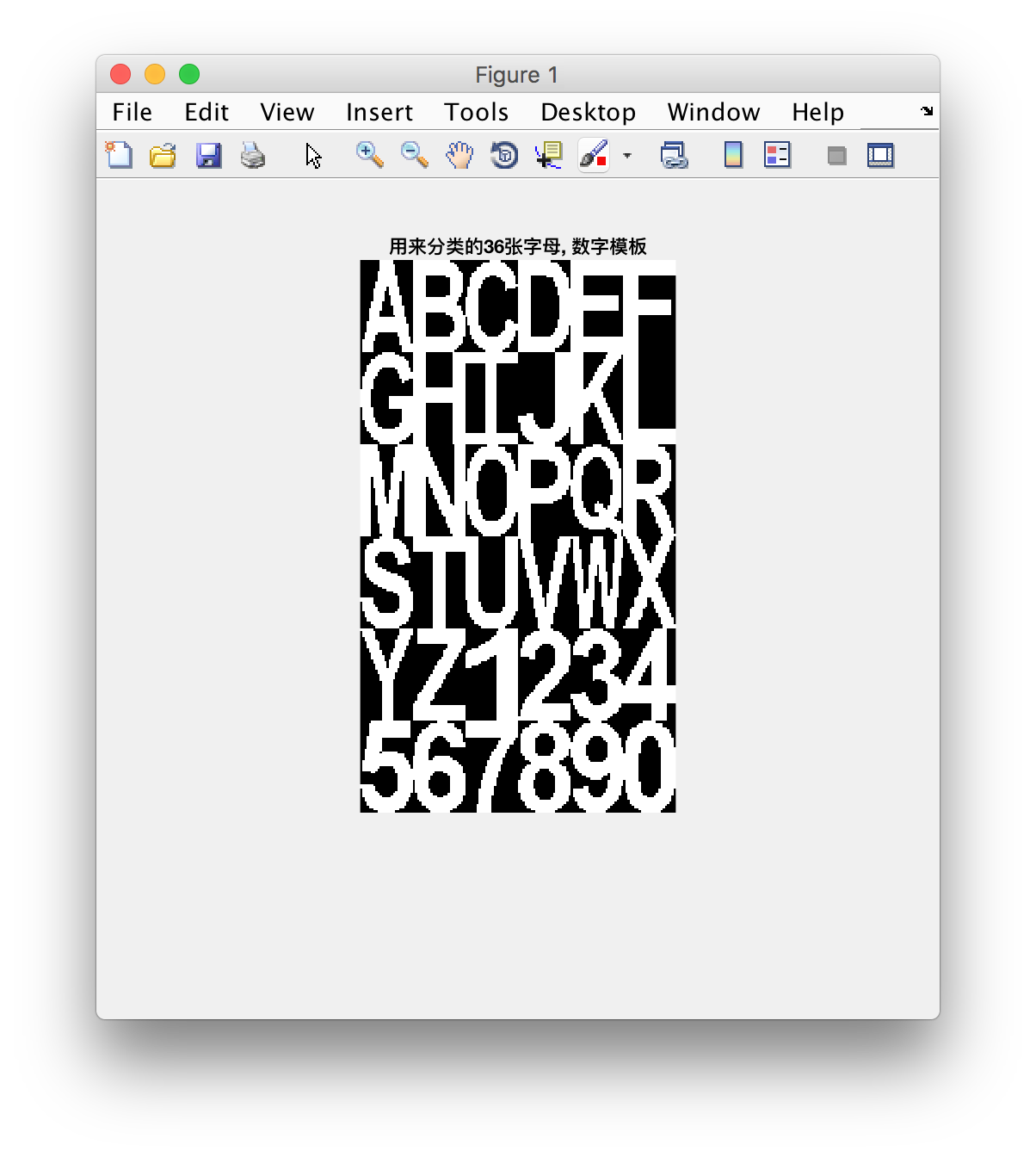
6. 模式识别
6.1 矩阵相似度
具体的矩阵相似度计算公式如下
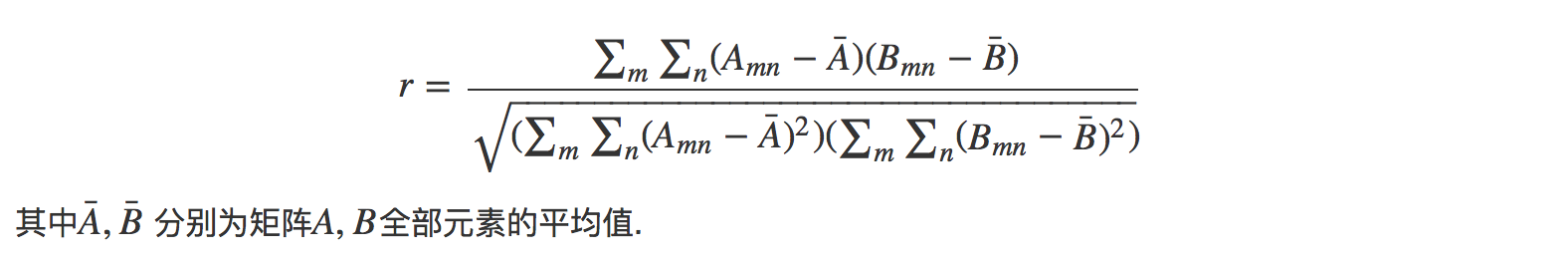
利用该公式可以计算两个矩阵的相关性, 这里我们计算的是待识别二值图像矩阵与模板矩阵的相似性, 以找到与其最相思的模板矩阵.
6.2 获取单个字符图像矩阵
由于一个待识别图像上并非只有一个字符, 我们需要将每一个字符单独提取出来进行识别, 具体步骤如下.
- 切割掉非文本的边缘部分
- 文本行切割
- 对一行文本逐个切割出单个字符
6.2.1 切割掉非文本的边缘部分
首先我们需要定义一个切割函数, 以将一个图片的字符部分切割出来, 消去不必要的空白区域.
function img_out=clip(img_in)
[f c]=find(img_in);
img_out=img_in(min(f):max(f),min(c):max(c));%切割图像
6.2.1 文本行切割
由于文本图像上的字符都是一行一行的, 所以我们可以一行一行的逐行识别, 这里定义一个函数将第一行字符切割出来, 如下所示.
function [fl re]=lines(im_texto)
%对文件进行分行
% im_texto为输入图像; fl->检测到的第一行文本; re->剩余的文本行
% 样例:
% im_texto=imread('TEST_3.jpg');
% [fl re]=lines(im_texto);
% subplot(3,1,1);imshow(im_texto);title('INPUT IMAGE')
% subplot(3,1,2);imshow(fl);title('FIRST LINE')
% subplot(3,1,3);imshow(re);title('REMAIN LINES')
im_texto=clip(im_texto);
num_filas=size(im_texto,1);
%subplot(1,3,1)
%imshow(im_texto)
for s=1:num_filas
%找出第一行文本结束的空白处
if sum(im_texto(s,:))==0
nm=im_texto(1:s-1, :); % 第一行文本的图像矩阵
rm=im_texto(s:end, :);% 剩余文本的图像矩阵
fl = clip(nm);
re=clip(rm);
%subplot(1,3,2);imshow(fl);
%subplot(1,3,3);imshow(re);
break
else
fl=im_texto;%该图像只有一行文本
re=[ ];
end
end

6.2.3 对一行文本逐个切割出单个字符
有了每一个行的字符, 更进一步的, 我们需要得到每一个字符以已经进行匹配, 我们可以利用bwlabel函数得到一行文本上的每一个字符的图像矩阵.
6.3 对单个字符矩阵进行识别
有了上述处理过程, 我们接下来只需要对切割得到的多组字符图像进行逐个识别并输出结果即可.
定义一个匹配函数
function letter=read_letter(imagn,num_letras)
% 计算模板与输入图像的相似性, 找出与其最相似的模板
% 输入为最相似模板的编号(如A,B)
% 输入图像矩阵的维度必须为 42 X 24.
% 样例:
% imagn=imread('D.bmp');
% letter=read_letter(imagn)
global templates
comp=[ ];
for n=1:num_letras
sem=corr2(templates{1,n},imagn);
comp=[comp sem];
end
vd=find(comp==max(comp));
%====================================
if vd==1
letter='A';
elseif vd==2
letter='B';
elseif vd==3
letter='C';
elseif vd==4
letter='D';
elseif vd==5
letter='E';
elseif vd==6
letter='F';
elseif vd==7
letter='G';
elseif vd==8
letter='H';
elseif vd==9
letter='I';
elseif vd==10
letter='J';
elseif vd==11
letter='K';
elseif vd==12
letter='L';
elseif vd==13
letter='M';
elseif vd==14
letter='N';
elseif vd==15
letter='O';
elseif vd==16
letter='P';
elseif vd==17
letter='Q';
elseif vd==18
letter='R';
elseif vd==19
letter='S';
elseif vd==20
letter='T';
elseif vd==21
letter='U';
elseif vd==22
letter='V';
elseif vd==23
letter='W';
elseif vd==24
letter='X';
elseif vd==25
letter='Y';
elseif vd==26
letter='Z';
%====================================
elseif vd==27
letter='1';
elseif vd==28
letter='2';
elseif vd==29
letter='3';
elseif vd==30
letter='4';
elseif vd==31
letter='5';
elseif vd==32
letter='6';
elseif vd==33
letter='7';
elseif vd==34
letter='8';
elseif vd==35
letter='9';
else
letter='0';
end
利用此函数, 输入为待识别字符, 输出即为与其最相似模板矩阵的字符.
最后将上面所做的工作结合起来, 即可完成我们的OCR系统.
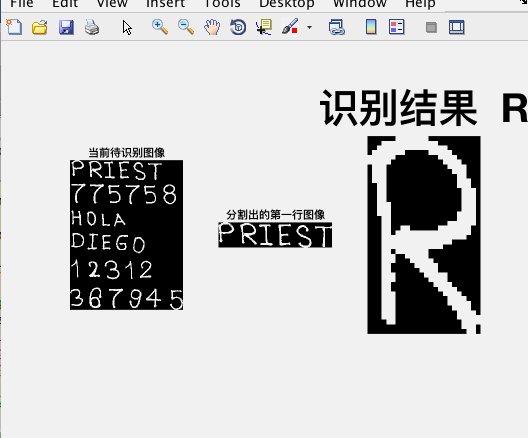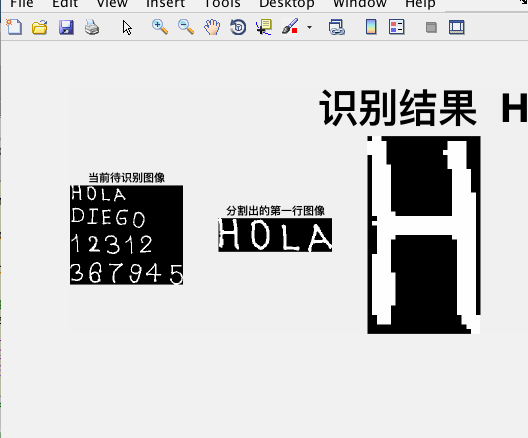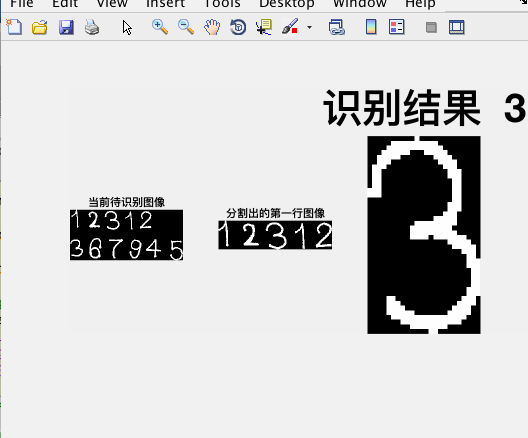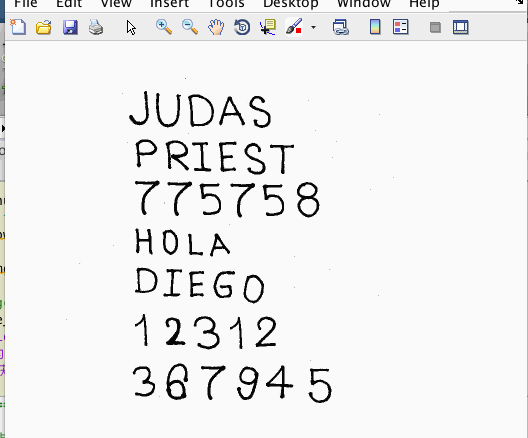
%% ==================== 第七部分: 循环分割文本图像并识别 ====================
fprintf(fid, '字符识别结果\n');
disp('Step 6: 开始识别全部文本....')
while 1
% lines函数用来对文本进行行分割
% 与上面的分割原理一样, 只是封装进了函数
subplot(1,3,1)
imshow(re)
title('当前待识别图像')
[fl re]=lines(re);
subplot(1,3,2)
imshow(fl)
title('分割出的第一行图像')
% 令imgn为第一行文本图像
imgn=fl;
% 显示分割后的第一行图像
%-----------------------------------------------------------------
% 找到每行文本图像的连通分量及其标号
[L Ne] = bwlabel(imgn);
% 对每一个连通分量(一个待识别字符)进行识别
for n=1:Ne
[r,c] = find(L==n);
% 提取单个字符
n1=imgn(min(r):max(r),min(c):max(c));
% 单个字符图像矩阵大小调整 , 使其矩阵大小与模板字符相同的
img_r=imresize(n1,[42 24]);
% 绘制调整后的单个字符
%-------------------------------------------------------------------
% 与模板进行匹配, 找到与其相似的模板, 并作为其识别结果
letter=read_letter(img_r,num_letras);
% 保存识别结果
subplot(1,3,3)
imshow(img_r);
title(sprintf('识别结果: %s', letter), 'fontsize', 40)
pause(0.35)
word=[word letter];
end
% 将本行识别结果写入txt文件
fprintf(fid,'%s\n',word);
% 清除本行识别结果, 为下一行识别作准备
word=[ ];
% 识别结束后跳出
if isempty(re)
break
end
end